Logging is basically used for capturing information about package execution itself - errors encountered, execution time for the package or steps within the package, data flow buffer
details, etc. Auditing is typically information about the data - how many records inserted,
updated, and deleted; when it was done; what was the source; who ran the package; what
machine did it run on, etc.
Thursday, August 30, 2012
Saturday, August 25, 2012
Nested Loop
The nested loop join works by looping through all the rows of one input and for each row looping through all the rows of the other input, looking for matches. The nested loop join works best when one or both of the input row sets is small. Since the input that is chosen as the second is read as many times as there are rows in the outer, this join can get very expensive as the size of the inputs increases.
For more detail on the nested loop, see Craig Freedman’s post
Merge Join
The merge join works by running through the two inputs, comparing rows and outputting matched rows. Both inputs must be sorted on the joining columns for this join to be possible. Since both inputs are only read once, this is an efficient join for larger row sets. This efficiency may be offset by the sorted requirement. If the join column is not indexed so as to retrieve the data already sorted, then an explicit sort is required.
For more detail on the merge join, see Craig Freedman’s post
Hash Join
The hash join is one of the more expensive join operations, as it requires the creation of a hash table to do the join. That said, it’s the join that’s best for large, unsorted inputs. It is the most memory-intensive of any of the joins
The hash join first reads one of the inputs and hashes the join column and puts the resulting hash and the column values into a hash table built up in memory. Then it reads all the rows in the second input, hashes those and checks the rows in the resulting hash bucket for the joining rows.
Copied from SQL In The Wild
The nested loop join works by looping through all the rows of one input and for each row looping through all the rows of the other input, looking for matches. The nested loop join works best when one or both of the input row sets is small. Since the input that is chosen as the second is read as many times as there are rows in the outer, this join can get very expensive as the size of the inputs increases.
For more detail on the nested loop, see Craig Freedman’s post
Merge Join
The merge join works by running through the two inputs, comparing rows and outputting matched rows. Both inputs must be sorted on the joining columns for this join to be possible. Since both inputs are only read once, this is an efficient join for larger row sets. This efficiency may be offset by the sorted requirement. If the join column is not indexed so as to retrieve the data already sorted, then an explicit sort is required.
For more detail on the merge join, see Craig Freedman’s post
Hash Join
The hash join is one of the more expensive join operations, as it requires the creation of a hash table to do the join. That said, it’s the join that’s best for large, unsorted inputs. It is the most memory-intensive of any of the joins
The hash join first reads one of the inputs and hashes the join column and puts the resulting hash and the column values into a hash table built up in memory. Then it reads all the rows in the second input, hashes those and checks the rows in the resulting hash bucket for the joining rows.
Copied from SQL In The Wild
Covering Index VS Composite Index
Composite index: An index that contains more than one column. In both SQL Server 2005 or higher, you can include up to 16 columns in an index, as long as the index doesn’t exceed the 900 byte limit. Both clustered and nonclustered indexes can be composite indexes.
Covering index: A type of index that includes all the columns that are needed to process a particular query. For example, your query might retrieve the FirstName and LastName columns from a table, based on a value in the ContactID column. You can create a covering index that includes all three columns.
If an index has more than a column in it, it is called a composite index. There is no KEYWORD associated with it. The best performing indexes are narrow with good selectivity.
A table can have maximum 1 clustered index since the data is layed out according to this index. The leaf level of the B-TREE is the data pages. One application is range searches. The INT IDENTITY(1,1) PRIMARY KEY is usually the clustered index.
A table can have 0 or more non-clustered indexes.
An index can include non-key columns. It is called a covering index if It has all the columns needed to run certain queries.
Covering index: A type of index that includes all the columns that are needed to process a particular query. For example, your query might retrieve the FirstName and LastName columns from a table, based on a value in the ContactID column. You can create a covering index that includes all three columns.
If an index has more than a column in it, it is called a composite index. There is no KEYWORD associated with it. The best performing indexes are narrow with good selectivity.
A table can have maximum 1 clustered index since the data is layed out according to this index. The leaf level of the B-TREE is the data pages. One application is range searches. The INT IDENTITY(1,1) PRIMARY KEY is usually the clustered index.
A table can have 0 or more non-clustered indexes.
An index can include non-key columns. It is called a covering index if It has all the columns needed to run certain queries.
Union, Union All, Except, and Intersect
- The UNION operator combines the output of two query expressions into a single result set. Query expressions are executed independently, and their output is combined into a single result table.
- The purpose of the SQL UNION ALL command is also to combine the results of two queries together. The difference between UNION ALL and UNION is that, while UNIONonly selects distinct values, UNION ALLselects all values.The purpose of the SQL UNION ALL command is also to combine the results of two queries together. The difference between UNION ALL and UNION is that, while UNIONonly selects distinct values, UNION ALLselects all values.
· The EXCEPT
operator evaluates the output of two query expressions and returns the
difference between the results. The result set contains all rows returned from
the first query expression except those rows that are also returned from the
second query expression.
· The INTERSECT
operator evaluates the output of two query expressions and returns only the rows
common to each.
Group By (Rollup & Cube & Grouping Sets)
Rollup, CUBE, and Grouping Sets are all extensions of the Group By Clause.
The GROUP BY clause can be used in a SELECT statement to collect data across multiple records and group the results by one or more columns.
The GROUPING SETS operator can generate the same result set as that generated by using a simple GROUP BY, ROLLUP, or CUBE operator. When all the groupings that are generated by using a full ROLLUP or CUBE operator are not required, you can use GROUPING SETS to specify only the groupings that you want. The GROUPING SETS list can contain duplicate groupings; and, when GROUPING SETS is used with ROLLUP and CUBE, it might generate duplicate groupings. Duplicate groupings are retained as they would be by using UNION ALL.
The GROUP BY clause can be used in a SELECT statement to collect data across multiple records and group the results by one or more columns.
ROLLUP enables a SELECT statement to calculate multiple levels of
subtotals across a specified group of dimensions. It also calculates a grand
total. ROLLUP is
a simple extension to the GROUP
BY
clause, so its syntax is extremely easy to use. The ROLLUP extension is highly
efficient, adding minimal overhead to a query. CUBE enables a SELECT statement to calculate subtotals for all
possible combinations of a group of dimensions. It also calculates a grand
total. This is the set of information typically needed for all cross-tabular
reports, so CUBE can
calculate a cross-tabular report with a single SELECT statement. Like ROLLUP, CUBE is a simple extension
to the GROUP BY clause, and its syntax
is also easy to learn. The GROUPING SETS operator can generate the same result set as that generated by using a simple GROUP BY, ROLLUP, or CUBE operator. When all the groupings that are generated by using a full ROLLUP or CUBE operator are not required, you can use GROUPING SETS to specify only the groupings that you want. The GROUPING SETS list can contain duplicate groupings; and, when GROUPING SETS is used with ROLLUP and CUBE, it might generate duplicate groupings. Duplicate groupings are retained as they would be by using UNION ALL.
Cross Apply VS Outer Apply
The APPLY operator is required when you have to use table-valued function in the query, but it can also be used with an inline SELECT statements.
The
CROSS APPLY operator returns only those rows from left table expression (in its
final output) if it matches with right table expression. In other words, the
right table expression returns rows for left table expression match only.
Whereas the OUTER APPLY operator returns all the rows from left table
expression irrespective of its match with the right table expression. For those
rows for which there are no corresponding matches in right table expression, it
contains NULL values in columns of right table expression. So you might now
conclude, the CROSS APPLY is semantically equivalent to INNER JOIN (or to be
more precise it’s like a CROSS JOIN with a correlated sub-query) with an
implicit join condition of 1=1 whereas OUTER APPLY is semantically equivalent
to LEFT OUTER JOIN.
Cross Apply returns only rows from the outer table that produces a result set from the table-valued function.
Outer Apply returns both rows that produce a result set and rows that do not, with NULL values in the columns produced by the table-valued function.
RaiseError
RaiseError generates an error message and initiates error processing for the system.
RaisEerror can either reference defined message stored in the sys.messages catalogview or build a message dynamically. The message is returned as a server error message to the calling application or to an associated CATCH block of a TRY…ATCH construct.

Merge Statement
MERGE is a new feature that provides an efficient way to perform multiple DML operations. In previous versions of SQL Server, we had to write separate statements to INSERT, UPDATE, or DELETE data based on certain conditions, but now, using MERGE statement we can include the logic of such data modifications in one statement that even checks when the data is matched then just update it and when unmatched then insert it. One of the most important advantages of MERGE statement is all the data is read and processed only once.

@@error
@@Error: Returns the value of the last t-sql statement's error message, if there was an error. @@ERROR returns 0 if the statement executed successfully. You can view the text associated with an @@ERROR error number in the sysmessages system table.
@@error is cleared and reset on each statement executed, so check it immediately following the statement validated, or save it to a local variable that can be checked later.
@@error is cleared and reset on each statement executed, so check it immediately following the statement validated, or save it to a local variable that can be checked later.
Stored Procedure VS User-Defined Functions
UDF can be used in the SQL statements anywhere in the WHERE/HAVING/SELECT section where as Stored procedures cannot be. UDFs that return tables can be treated as another rowset. This can be used in JOINs with other tables. Inline UDF's can be thought of as views that take parameters and can be used in JOINs and other Rowset operations.
- UDF can be used in the SQL statements anywhere in the WHERE/HAVING/SELECT section where as Stored procedures cannot be.
- UDFs that return tables can be treated as another rowset. This can be used in JOINs with other tables.
- Inline UDF's can be though of as views that take parameters and can be used in JOINs and other Rowset operations.
- Unlike
Stored Procedure DML operations, like INSERT/UPDATE/DELETE, are not allowed in
UDF.
- A stored procedure can
have both input and output parameters whereas UDF can only have input
parameters.
UDF can be directly selected from, whereas a stored procedure requires one to insert the results into a tempory table or table variabl
- Stored procedures different than multi-line TVF is that the optimizer can use statistics to create a better query plan for a stored procedure; however, no statistics are maintained on Multi-line UDFs, so the optimizer has to guess at the number of rows, which can lead to a sub-optimal plan.
- Stored procs can create a table but can’t return table.
Functions can create, update and delete the table variable. It can return a table - Stored Procedures can affect the state of the database by using insert,
delete, update and create operations.
Functions cannot affect the state of the database which means we cannot perform insert, delete, update and create operations operations on the database. - Stored procedures are stored in database in the compiled form.
Function are parsed and conpiled at runtime only. - Stored procs can be called independently using exec keyword. Stored
procedure cannot be used in the select/where/having clause.
Function are called from select/where/having clause. Even we can join two functions. - Stored procedure allows getdate () or other non-deterministic functions can
be allowed.
Function won’t allow the non-deterministic functions like getdate(). - In Stored procedures we can use transaction statements. We can’t use in functions.
- The stored procedures can do all the DML operations like insert the new
record, update the records and delete the existing records.
The function won’t allow us to do the DML operations in the database tables like in the stored procedure. It allows us to do only the select operation. It will not allow to do the DML on existing tables. But still we can do the DML operation only on the table variable inside the user defined functions. - Temporary tables (derived) can be created in stored procedures.
It is not possible in case of functions. - when sql statements encounters an error, T-SQL will ignore the error in a
SPROC and proceed to the next statement in the remaining code.
In case of functions, T-SQL will stop execution of next statements.
Here's the full list of Differences:
Delete VS Truncate
| Truncate | Delete |
| TRUNCATE is a DDL command | DELETE is a DML command |
| TRUNCATE TABLE always locks the table and page but not each row | DELETE statement is executed using a row lock, each row in the table is locked for deletion |
| Cannot use Where Condition | We can specify filters in where clause |
| It Removes all the data | It deletes specified data if where condition exists. |
| TRUNCATE TABLE cannot activate a trigger because the operation does not log individual row deletions. | Delete activates a trigger because the operation are logged individually. |
| Faster in performance wise, because it is minimally logged in transaction log. | Slower than truncate because, it maintain logs for every record |
| Drop all object’s statistics and marks like High Water Mark free extents and leave the object really empty with the first extent. zero pages are left in the table | keeps object’s statistics and all allocated space. After a DELETE statement is executed,the table can still contain empty pages. |
| TRUNCATE TABLE removes the data by deallocating the data pages used to store the table data and records only the page deallocations in the transaction lo | The DELETE statement removes rows one at a time and records an entry in the transaction log for each deleted row |
| If the table contains an identity column, the counter for that column is reset to the seed value that is defined for the column | DELETE retain the identity |
| Restrictions on using Truncate Statement 1. Are referenced by a FOREIGN KEY constraint. 2. Participate in an indexed view. 3. Are published by using transactional replication or merge replication. | Delete works at row level, thus row level constrains apply |
Datepart,Datename DateAdd, DateDiff, Date
DatePart- Returns an integer tat represents the specified datepart of the specified date.
DATEPART (DatePart, Date)
DateName- Returns a character string that represents the specified datepart of the specified date.
DATENAME (DatePart, Date)
DateAdd-Returns a specified date with the specified number interval added to a specified datepart of that date.
DATEADD (DatePart, number, date)
DateDiff-Returns the time between two dates.
DATEDIFF (DatePart, StartDate, EndDate)
DATEPART (DatePart, Date)
DateName- Returns a character string that represents the specified datepart of the specified date.
DATENAME (DatePart, Date)
DateAdd-Returns a specified date with the specified number interval added to a specified datepart of that date.
DATEADD (DatePart, number, date)
DateDiff-Returns the time between two dates.
DATEDIFF (DatePart, StartDate, EndDate)
Try...Catch
Errors in tsql can be processed by using a TRY…CATCH construct which contains two parts: a try block and a catch block. When an error condition is detected in a t-sql statement that is inside a try block, control is passed to a catch block where the error can be processed.


Materialized View/Index View
A View created with a unique clustered index is known as an Indexed View or Materialized View.
Unlike views, an indexed view exists on the disk like a table in which the clustered index is created. Once a Clustered Index is created you may create non-clustered indexes on the view.
Unlike views, an indexed view exists on the disk like a table in which the clustered index is created. Once a Clustered Index is created you may create non-clustered indexes on the view.
Tuesday, August 21, 2012
Script Task Vs Script Component
The Script component hosts script and enables a package to include and run custom script code.
You can use the Script component in packages for the following purposes:
- Apply multiple transformations to data instead of using multiple transformations in the data flow. For example, a script can add the values in two columns and then calculate the average of the sum.
- Access business rules in an existing .NET assembly. For example, a script can apply a business rule that specifies the range of values that are valid in an Income column.
- Use custom formulas and functions in addition to the functions and operators that the Integration Services expression grammar provides. For example, validate credit card numbers using the LUHN formula.
- Validate column data and skip records that contain invalid data. For example, a script can assess the reasonableness of a postage amount and skip records with extremely high or low amounts.
The Script component provides an easy and quick way to include custom functions in a data flow. However, if you plan to reuse the script code in multiple packages, you should consider programming a custom component instead of using the Script component. For more information, see Extending the Data Flow with Custom Components.
The Script component can be used as a source, a transformation, or a destination. This component supports one input and multiple outputs. Depending on how the component is used, it supports either an input or outputs or both. The script is invoked by every row in the input or output.
- If used as a source, the Script component supports multiple outputs.
- If used as a transformation, the Script component supports one input and multiple outputs.
- If used as a destination, the Script component supports one input.
The Script component does not support error outputs.
You can configure the Script component in the following ways:
- Select input columns to reference.
- Provide the script that the component runs.
- Specify whether the script is precompiled.
- Provide comma-separated lists of read-only and read/write variables.
- Add more outputs, and add output columns to which the script assigns values.
The Script task provides code to perform functions that are not available in the built-in tasks and transformations that SQL Server 2005 Integration Services provides. The Script task can also combine functions in one script instead of using multiple tasks and transformations. The code is custom Microsoft Visual Basic .NET code that is compiled and executed at package run time.
You can use the Script task for the following purposes:
- Access data using other technologies that are not supported by built-in connection types. For example, a script can use Active Directory Service Interfaces (ADSI) to access and extract user names from Active Directory.
- Create a package-specific performance counter. For example, a script can create a performance counter that is updated while a complex or poorly performing task runs.
- Replace data in the source with different data in the destination. For example, a script can replace a two-digit state code in the source data with the state name in the destination data.
- Validate important columns in the source data and skip records that contain invalid data to prevent them from being copied to the destination. For example, a script can assess the reasonableness of a postage amount and skip records with extremely high or low amounts
Monday, August 20, 2012
Execution Plan
Execution plans can tell you how a query will be executed, or how a
query was executed. They are, therefore, the DBA's primary means of
troubleshooting a poorly performing query. You can use the estimated execution plan to estimate how the query will run and perform. It may not be exact however it will be close. The reason it may not be exact is because when you execute your query it might have planned to go that way of the estimated plan but might have encountered a problem along the way and it might have to take a detour and go another way or use something different. The Actual Execution Plan is returned after the query has been executed and gives you the chance to see how well or badly it performed. It could very well help you realize what you can replace and how to make your query perform better.
After Trigger and Instead Of Trigger
The following is from Technet:
AFTER triggers are stored procedures that occur after a data manipulation statement has occurred in the database, such as a delete statement. DDL triggers are new to SQL Server 2005, and allow you to respond to object definition level events that occur in the database engine, such as a DROP TABLE statement. INSTEAD-OF triggers are objects that will execute instead of data manipulation statements in the database engine. For example, attaching an INSTEAD-OF INSERT trigger to a table will tell the database engine to execute that trigger instead of executing the statement that would insert values into that table.
Perhaps a more functional reason to use an INSTEAD-OF trigger would be to add the trigger to a view. Adding an INSTEAD-OF trigger to a view essentially allows you to create updateable views. Updateable views allow you to totally abstract your database schema so you can potentially design a system in such a way that your database developers do not have to worry about the OLTP database schema and instead rely upon a standard set of views for data modifications.
AFTER triggers are stored procedures that occur after a data manipulation statement has occurred in the database, such as a delete statement. DDL triggers are new to SQL Server 2005, and allow you to respond to object definition level events that occur in the database engine, such as a DROP TABLE statement. INSTEAD-OF triggers are objects that will execute instead of data manipulation statements in the database engine. For example, attaching an INSTEAD-OF INSERT trigger to a table will tell the database engine to execute that trigger instead of executing the statement that would insert values into that table.
Why use an INSTEAD-OF trigger?
INSTEAD-OF triggers are very powerful objects in SQL Server. They allow the developer to divert the database engine to do something different than what the user is trying to do. An example of this would be to add an INSTEAD-OF trigger to any table in your database that rolls back transactions on tables that you do not want modified. You must be careful when using this method because the INSTEAD-OF trigger will need to be disabled before any specified modifications can occur to this table.Perhaps a more functional reason to use an INSTEAD-OF trigger would be to add the trigger to a view. Adding an INSTEAD-OF trigger to a view essentially allows you to create updateable views. Updateable views allow you to totally abstract your database schema so you can potentially design a system in such a way that your database developers do not have to worry about the OLTP database schema and instead rely upon a standard set of views for data modifications.
Cascading parameters
Cascading parameters provide a way of managing large amounts of report data. You can define a set of related parameters so that the list of values for one parameter depends on the value chosen in another parameter. For example, the first parameter is independent and might present a list of product categories. When the user selects a category, the second parameter is dependent on the value of the first parameter. Its values are updated with a list of subcategories within the chosen category. When the user views the report, the values for both the category and subcategory parameters are used to filter report data.
The above definition is from Technet: http://technet.microsoft.com/en-us/library/dd255197.aspx
The above definition is from Technet: http://technet.microsoft.com/en-us/library/dd255197.aspx
Friday, August 17, 2012
Differences between....
a.
merge and merge join-- Merge Acts like a union all in T-sql but you can provide only two input
to this transformation which must be pre- sorted and merge join joins the two
datasets like T-SQL joins(inner join , left join, right join )
b.
union and union all---- The union command is used to select related information
from two tables but with union distinct values are selected. The union all
command is equal to the union command, except union all selects all values and
will not get rid of duplicate rows.
c.
merge join and union all--- Merge can only accept two datasets while
Union All can accept more than two datasets for input. The second difference is
that Merge requires both datasets to be sorted while Union All does not require
sorted datasets
d.
row sampling and percentage sampling--- Row sampling is used to randomly
select some rows and move them as output to the required process as and when
required to divide the rows. Percentage Sampling on the other hand, selects
rows randomly by percentage.
e.
dts and ssis---- DTS is a set of objects using an ETS tool to extract,
transform, and load information to or from a database; SSIS is an ETL tool
provided by Microsoft to extract data from different sources.
f.
pivot and unpivot---- Pivot will convert rows to columns and un-pivot will go the other way,
columns to rows
g.
scnhronous transformation and
ascnchronous transformation--- A synchronous transformation processes incoming rows and passes them on
in the data flow one row at a time. Output is synchronous with input, meaning
that it occurs at the same time. The
transformation does not need information about other rows in the data set. The
Rows are grouped into Buffers as they pass from one component to the next.
Meanwhile, in an asynchronous
transformation, you cannot pass each row along in the data flow as it is
processed, but instead must output data asynchronously, or at a different time,
than the input.
h.
look-up and merge join--- The Lookup transformation performs lookups by joining data in input
columns with columns in a reference dataset.
Lookup uses an ole db connection manager. While a merge join combines
two sorted datasets using a FULL, LEFT, or INNER join.
Wednesday, August 15, 2012
OLTP VS OLAP and Data Mining and Data Warehouse
OLTP is a data processing system that records all of the business transactions as they occur. This can be characterized by many concurrent users activly adding and modifying data.
OLAP is a technology that uses multi-dimensional structures to provide fast access to data for analysis and business decision making purposes.
Data Mining is the extraction or "mining" of a large amount of knowledge from a data or data warehouse.
Data Warehouse is a centralized repository that stores data from multiple information sources and transforms them into a multi-dimensional data model for efficient querying and analysis.

OLAP is a technology that uses multi-dimensional structures to provide fast access to data for analysis and business decision making purposes.
Data Mining is the extraction or "mining" of a large amount of knowledge from a data or data warehouse.
Data Warehouse is a centralized repository that stores data from multiple information sources and transforms them into a multi-dimensional data model for efficient querying and analysis.

cast and convert
cast and convert-- converts an expression from one data type to another.
cast and convert have similar functionality. However, Cast is Ansi Standard, while Convert is for sql server only and convert has more functionality and is mainly used for date/time functions.
Although their performance is also similar, their syntax and potential usage is slightly different.
Syntax for CAST:
CAST ( expression AS data_type [ (length ) ])
Syntax for CONVERT:
CONVERT ( data_type [ ( length ) ] ,expression [ ,style ] )

User-defined funcions
User-Defined Functions
that allow you to define your own T-SQL functions that can accept zero or more
parameters and return a single scalar data value or a table data type.
2 types
2 types
1.Scaler UDF- when it executes, it gives you the
single value
2.Table Valued UDF- when it executes, it gives you the result set (table)
@@identity, scope identity, and ident_current
SELECT
@@IDENTITY
It returns the last identity value produced on a connection, regardless of the table that produced the value, and regardless of the scope of the statement that produced the value.
It returns the last identity value produced on a connection, regardless of the table that produced the value, and regardless of the scope of the statement that produced the value.
SELECT
SCOPE_IDENTITY ()
It returns the last identity value produced on a connection and by a statement
in the same scope, regardless of the table that produced the value.
scope_identity(), like @@identity, will return the last identity value created
in the current session, but it will also limit it to your current scope as
well. In other words, it will return the last identity value that you
explicitly created, rather than any identity that was created by a trigger or a
user defined function.
SELECT
IDENT_CURRENT (‘tablename’)
It returns the last identity value produced in a table, regardless of the connection that created the value, and regardless of the scope of the statement that produced the value.
ident_current is not limited by scope and session; it is limited to a specified table. ident_current returns the identity value generated for a specific table in any session and any scope.
It returns the last identity value produced in a table, regardless of the connection that created the value, and regardless of the scope of the statement that produced the value.
ident_current is not limited by scope and session; it is limited to a specified table. ident_current returns the identity value generated for a specific table in any session and any scope.
Local and Global Temporary Tables and Table Variables
Local temporary tables are visible only to their creators during the same connection to an instance of SQL Server as when the tables were first created or referenced. Local temporary tables are deleted after the user disconnects from the instance of SQL Server.
Global temporary tables are visible to any user and any connection after they are created, and are deleted when all users that are referencing the table disconnect from the instance of SQL Server.
Some More Definitions from StackOverFlow:
DECLARE @t TABLE) are visible only to the theconnection that creates it, are stored in RAM, and are deleted when
the batch or stored procedure ends.
CREATE TABLE #t) are visible only to the connection that creates it, and are deleted when the connection is closed.CREATE TABLE ##t) are visible to everyone, and are deleted when the connection that created it is closed.USE tempdb CREATE TABLE t) are visible to everyone, and are deleted when the server is restarted. What is NOLOCK?
The NOLOCK query optimizer hint is generally considered good practice in order to improve concurrency on a busy system. When the NOLOCK hint is included in a Select Statement no locks are taken when data is read. Of course then the result of that would be a dirty read, which means that another process could be updating the data at the exact same time you are reading it. The advantage to performance is that, you reading the data will not block updates from taking place and the updates will not block you from reading the data. Also, select statements take Shared (Read) lock which means that multiple select statements are allowed simultaneous access, but other processes are blocked from modifying the data.
Dirty Reads and Phantoms
Dirty Read occurs when a user reads data that has not been commited yet, uncommited data. An example would be when Person A is working on a transaction and makes some changes but does not commit the data and looks at another transaction. Meanwhile Person B comes to look at the same data that person A just made some changes to. Person B is looking at the data, the uncommited data, before the changes were made, causing a dirty read to occur.
Phantom Read happens when data seems to have mysteriously appeared. Data getting changed in current transaction by other transactions is called Phantom Reads. New rows can be added by other transactions, so you get different number of rows by firing same query in current transaction.
Phantom Read happens when data seems to have mysteriously appeared. Data getting changed in current transaction by other transactions is called Phantom Reads. New rows can be added by other transactions, so you get different number of rows by firing same query in current transaction.
Isolation Level
Isolation Level: Controls the locking and row versioning behavior of Transact-SQL statements issued by a connection to SQL Server.<--msdn definition. Well basically it just controls the way locking works between transactions.
~The following information is from http://www.gavindraper.co.uk/2012/02/18/sql-server-isolation-levels-by-example/
As you can probably imagine this can cause some unexpected results in a variety of different ways. For example data returned by the select could be in a half way state if an update was running in another transaction causing some of your rows to come back with the updated values and some not to.
To see read uncommitted in action lets run Query1 in one tab of Management Studio and then quickly run Query2 in another tab before Query1 completes.
Query1
Query2
Notice that Query2 will not wait for Query1 to finish, also more importantly Query2 returns dirty data. Remember Query1 rolls back all its changes however Query2 has returned the data anyway, this is because it didn’t wait for all the other transactions with exclusive locks on this data it just returned what was there at the time.
There is a syntactic shortcut for querying data using the read uncommitted isolation level by using the NOLOCK table hint. You could change the above Query2 to look like this and it would do the exact same thing.
You can see an example of a read transaction waiting for a modify transaction to complete before returning the data by running the following Queries in separate tabs as you did with Read Uncommitted.
Query1
Query2
Notice how Query2 waited for the first transaction to complete before returning and also how the data returned is the data we started off with as Query1 did a rollback. The reason no isolation level was specified is because Read Committed is the default isolation level for SQL Server. If you want to check what isolation level you are running under you can run “DBCC useroptions”. Remember isolation levels are Connection/Transaction specific so different queries on the same database are often run under different isolation levels.
As before run Query1 then while its running run Query2
Query1
Query2
Notice that Query1 returns the same data for both selects even though you ran a query to modify the data before the second select ran. This is because the Update query was forced to wait for Query1 to finish due to the exclusive locks that were opened as you specified Repeatable Read.
If you rerun the above Queries but change Query1 to Read Committed you will notice the two selects return different data and that Query2 does not wait for Query1 to finish.
One last thing to know about Repeatable Read is that the data can change between 2 queries if more records are added. Repeatable Read guarantees records queried by a previous select will not be changed or deleted, it does not stop new records being inserted so it is still very possible to get Phantom Reads at this isolation level.
You know the drill by now run these queries side by side…
Query1
Query2
You’ll see that the insert in Query2 waits for Query1 to complete before it runs eradicating the chance of a phantom read. If you change the isolation level in Query1 to repeatable read, you’ll see the insert no longer gets blocked and the two select statements in Query1 return a different amount of rows.
So on the plus side your not blocking anyone else from modifying the data whilst you run your transaction but…. You’re using extra resources on the SQL Server to allocate each snapshot transaction the additional resources to store the snapshot data which can be quite significant if your transaction is working with a large amount of data.
To use the snapshot isolation level you need to enable it on the database by running the following command
If you rerun the examples from serializable but change the isolation level to snapshot you will notice that you still get the same data returned but Query2 no longer waits for Query1 to complete.
~The following information is from http://www.gavindraper.co.uk/2012/02/18/sql-server-isolation-levels-by-example/
Read Uncommitted
This is the lowest isolation level there is. Read uncommitted causes no shared locks to be requested which allows you to read data that is currently being modified in other transactions. It also allows other transactions to modify data that you are reading.As you can probably imagine this can cause some unexpected results in a variety of different ways. For example data returned by the select could be in a half way state if an update was running in another transaction causing some of your rows to come back with the updated values and some not to.
To see read uncommitted in action lets run Query1 in one tab of Management Studio and then quickly run Query2 in another tab before Query1 completes.
Query1
BEGIN TRANUPDATE Tests SET Col1 = 2--Simulate having some intensive processing here with a waitWAITFOR DELAY '00:00:10'ROLLBACK |
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTEDSELECT * FROM IsolationTests |
There is a syntactic shortcut for querying data using the read uncommitted isolation level by using the NOLOCK table hint. You could change the above Query2 to look like this and it would do the exact same thing.
SELECT * FROM IsolationTests WITH(NOLOCK) |
Read Committed
This is the default isolation level and means selects will only return committed data. Select statements will issue shared lock requests against data you’re querying this causes you to wait if another transaction already has an exclusive lock on that data. Once you have your shared lock any other transactions trying to modify that data will request an exclusive lock and be made to wait until your Read Committed transaction finishes.You can see an example of a read transaction waiting for a modify transaction to complete before returning the data by running the following Queries in separate tabs as you did with Read Uncommitted.
Query1
BEGIN TRANUPDATE Tests SET Col1 = 2--Simulate having some intensive processing here with a waitWAITFOR DELAY '00:00:10'ROLLBACK |
SELECT * FROM IsolationTests |
Repeatable Read
This is similar to Read Committed but with the additional guarantee that if you issue the same select twice in a transaction you will get the same results both times. It does this by holding on to the shared locks it obtains on the records it reads until the end of the transaction, This means any transactions that try to modify these records are force to wait for the read transaction to complete.As before run Query1 then while its running run Query2
Query1
SET TRANSACTION ISOLATION LEVEL REPEATABLE READBEGIN TRANSELECT * FROM IsolationTestsWAITFOR DELAY '00:00:10'SELECT * FROM IsolationTestsROLLBACK |
UPDATE IsolationTests SET Col1 = -1 |
If you rerun the above Queries but change Query1 to Read Committed you will notice the two selects return different data and that Query2 does not wait for Query1 to finish.
One last thing to know about Repeatable Read is that the data can change between 2 queries if more records are added. Repeatable Read guarantees records queried by a previous select will not be changed or deleted, it does not stop new records being inserted so it is still very possible to get Phantom Reads at this isolation level.
Serializable
This isolation level takes Repeatable Read and adds the guarantee that no new data will be added eradicating the chance of getting Phantom Reads. It does this by placing range locks on the queried data. This causes any other transactions trying to modify or insert data touched on by this transaction to wait until it has finished.You know the drill by now run these queries side by side…
Query1
SET TRANSACTION ISOLATION LEVEL SERIALIZABLEBEGIN TRANSELECT * FROM IsolationTestsWAITFOR DELAY '00:00:10'SELECT * FROM IsolationTestsROLLBACK |
INSERT INTO IsolationTests(Col1,Col2,Col3)VALUES (100,100,100) |
Snapshot
This provides the same guarantees as serializable. So what’s the difference? Well it’s more in the way it works, using snapshot doesn’t block other Queries from inserting or updating the data touched by the snapshot transaction. Instead it creates it’s own little snapshot of the data being read at that time, if you then read that data again in the same transaction it reads it from its snapshot, This means that even if another transaction has made changes you will always get the same results as you did the first time you read the data.So on the plus side your not blocking anyone else from modifying the data whilst you run your transaction but…. You’re using extra resources on the SQL Server to allocate each snapshot transaction the additional resources to store the snapshot data which can be quite significant if your transaction is working with a large amount of data.
To use the snapshot isolation level you need to enable it on the database by running the following command
ALTER DATABASE IsolationTestsSET ALLOW_SNAPSHOT_ISOLATION ON |
Summary
You should now have a good idea how each of the different isolation levels work. You can see how the higher the level you use the less concurrency you are offering and the more blocking you bring to the table. You should always try to use the lowest isolation level you can which is usually read committed.Lock Escalation
Lock escalation is the process of converting many fine-grain locks into fewer coarse-grain locks, reducing system overhead while increasing the probability of concurrency contention.
As the SQL Server Database Engine acquires low-level locks, it also places intent locks on the objects that contain the lower-level objects:
As the SQL Server Database Engine acquires low-level locks, it also places intent locks on the objects that contain the lower-level objects:
- When locking rows or index key ranges, the Database Engine places an intent lock on the pages that contain the rows or keys.
- When locking pages, the Database Engine places an intent lock on the higher level objects that contain the pages. In addition to intent lock on the object, intent page locks are requested on the following objects:
- Leaf-level pages of nonclustered indexes
- Data pages of clustered indexes
- Heap data pages
Tuesday, August 14, 2012
Locks
Shared Lock: It is used when you only need to read the data. It prevents users from performing dirty reads.
Exclusive Lock: As the name suggests, it is not compatible with any other lock. It prevents two people from updating or deleting data at the same time.
Update Lock: Indicates that you have a shared lock that's going to become an exclusive lock after doin your initial scan of the data (to figure out what, if needed, needs to be updated). If you do not change the data then it just stays as a shared lock.
Intent Lock: It's used to deal with object hierarchies. Intent locks has two purposes:
Exclusive Lock: As the name suggests, it is not compatible with any other lock. It prevents two people from updating or deleting data at the same time.
Update Lock: Indicates that you have a shared lock that's going to become an exclusive lock after doin your initial scan of the data (to figure out what, if needed, needs to be updated). If you do not change the data then it just stays as a shared lock.
Intent Lock: It's used to deal with object hierarchies. Intent locks has two purposes:
- Prevent other transactions from modifying the higher-level resource in a way that would invalidate the lock at the lower level.
- Improves the efficiency of the Database Engine in detecting lock conflicts at the higher level of granularity.
Report Server and Report Server Tempdb
Report Server is the primary database that stores all of the information about reports that was originally povided from the RDL files used to create and publish the reports to the report server database. Report Server also stores folder hierarchy and execution log information.
Report Server Tempdb: This database stores cached copies of reports that you can use to increase performance for many simultaneous users. By caching reports, you are making sure that they remain available to users even if the report server is restarted.
Report Server Tempdb: This database stores cached copies of reports that you can use to increase performance for many simultaneous users. By caching reports, you are making sure that they remain available to users even if the report server is restarted.
RDL
RDL (Report Definition Language): is a file extention for an XML file used for SSIS. RDL files contain calculations, charts, images, graphs, and texts and can be rendered into a variety of formats as needed.
Performance Tuning of Reports
This is again another broad topic, but here are a few useful tips:
- Optimize your report queries- you can use tools such as query analyzer and sql profiler to optimize your query. Database tuning advisor can suggest better indexes for your database.
- Look at the execution log table, see if you find anything running slow, it will help you determine what you need to optimize.
- Report caching: it allows temporary copies of a report to be stored and rendered to a user.
- Snapshot
- Execution Snapshot: is viewed from a report folder in report manager just like on-demand reports would be viewed.
- History Snapshot: Creates a report history and are viewed from the history tab of the report and can accumulate many copies.
IIF and Switch Functions
IIF Function returns one of two values depending on whether the expression is true or false.
 The Switch Function is useful when you have three or more conditions to test. It returns the value associated with the first expression in a series that evaluates to true.
The Switch Function is useful when you have three or more conditions to test. It returns the value associated with the first expression in a series that evaluates to true.



Role Based Security
Role-based Security: Reporting Services uses a role-based security model to control access to reports, folders, and other items that are managed by a report Server. The model maps a specific user or group to a role an the role describes how that user or group is to access a given report or item.
Tabular and Matrix reports
Tabular: The most basic type of report. Each column corresponds to a column selected from the database.
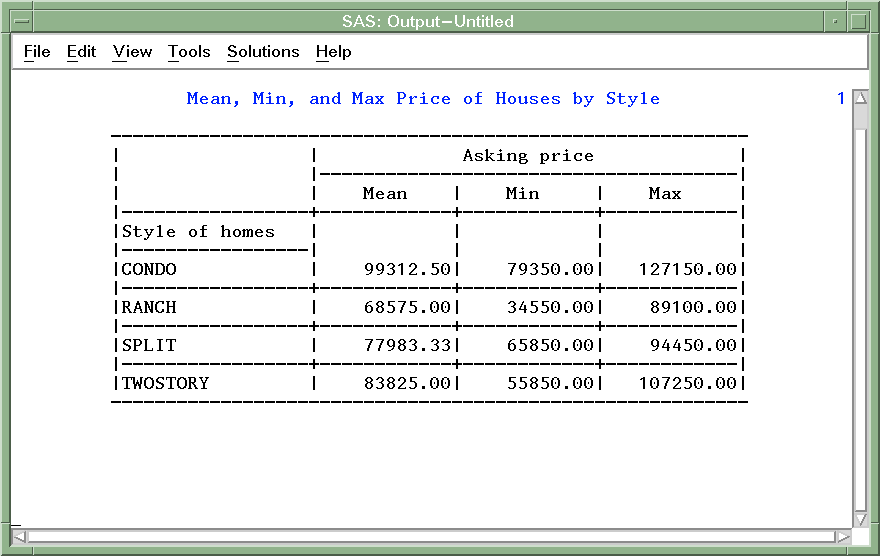
Matrix Report is a cross-tabulation of 4 groups of data:

Matrix Report is a cross-tabulation of 4 groups of data:
- One group of data is displayed across the page.
- One group of data is displayed down the page.
- One group of data is the cross-product, which determines all possible locations where the across and down data relate and places a cell in those locations.
- One group of data is displayed as the "filler" of the cells.
Subscriptions
Subscriptions: A standing request to deliver a report at specific time or in response to an event and then to have that report presented in a way that you define. Subscriptions can be used to schedule and then automate the delivery of a report to the intended audience. Basically, you are using subscription to publish your report. SSRS allows you to create two types of subscriptions:
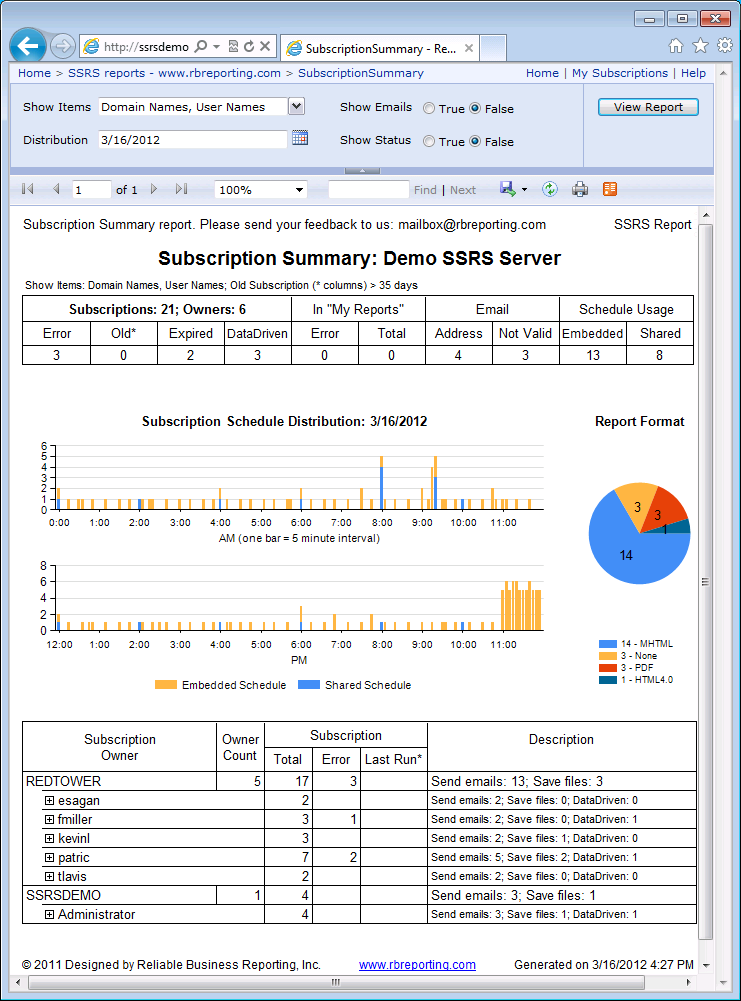
- Standard Subscription is used by any user having " Manage individual subscriptions" or "View a Report" permissions with Static Values for the parameters. It means whatever parameters the report expects needs to be provided at the time of subscription creation and cannot be changed at runtime.
- Data-Driven Subscription: Data or parameter values required during execution of the report, can come from a query including a recipient list, delivery method, and parameter values needed for each recipient report execution.
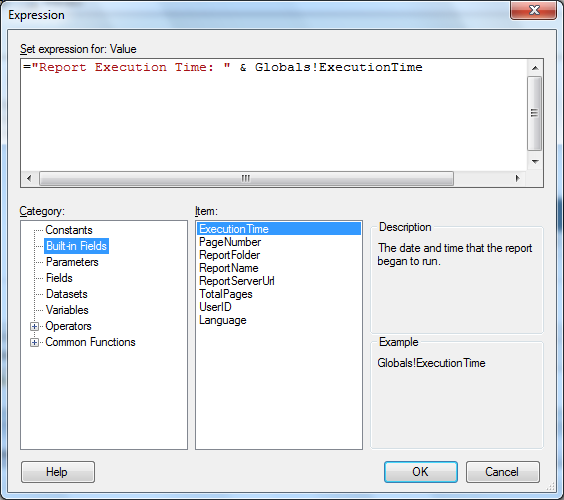
Expressions in Reports
Expressions are frequently used in reports to control content and the appearance of the report. You can also use expressions to specify or calculate values for parameters, queries, filters, and more. Expressions are written in Microsoft Visual Basic. An expression starts with an = sign followed by a combination of refrences to built-in collections such as dataset fields and parameters, constants, functions, and operators.
Report Builder and Ad-hoc Reports
Report Builder is an end user product that lets business users to create ad-hoc reports based on information stored in both relational and OLAP data stores. Report builder comes with templates for table, matrix, and chart reports.
Ad-hoc reports are the reports which a user can create using report model project. These reports have a predefined layout which is a standard layout from Microsoft. Users can select columns from different table or views and can generate the request as per requirement.

Ad-hoc reports are the reports which a user can create using report model project. These reports have a predefined layout which is a standard layout from Microsoft. Users can select columns from different table or views and can generate the request as per requirement.
Parameterized Report
A Parameterized Report uses input values to complete report or data processing. With a parameterized report, you can vary the output of a report based on values that are set when the report runs. Parameterized reports are frequently used for drillthrough and sub-reports cpnnecting reports with related data. Parameters are used in dataset queries to select report data, to filter the result set that the query returns, or to set layout properties used for showing and hiding parts of a report.


DrillDown And Drillthrough Reports
Drill through reports are the standard reports that are accessed through a hyperlink on a text box in the original report. Drill through is a term used to describe the act of exploring or browsing items like folders, files or related components.

Drill Down reports initially hide complexity and enable the user to toggle conditionally hidden report items to control how much detail data the user wants to see. Drill down reports must retrieve all of the possibl data that can be shown in the report. I recommend that you use drillthrough report if your report has a large amount of data.
Create a DrillDown Report posted by Ravi:
Drill Down reports initially hide complexity and enable the user to toggle conditionally hidden report items to control how much detail data the user wants to see. Drill down reports must retrieve all of the possibl data that can be shown in the report. I recommend that you use drillthrough report if your report has a large amount of data.
Create a DrillDown Report posted by Ravi:
Creating a Drill Down Report with SQL Server 2008
In SSRS we can generate drill down reports in very easy
way. To create Drill down reports, please follow the following steps.
Step1: Create New Report Project with one Shared DataSource with data query for generating report.
Step1: Create report by taking Table type report as shown bellow
 Step3: Now
Add Group for product by right clicking on Product Column as
shown bellow
Step3: Now
Add Group for product by right clicking on Product Column as
shown bellow
 Select Add
Parent group
Select Add
Parent group
 Selet
Product from Group By DropDown and check Add Group Header, then
click OK
Selet
Product from Group By DropDown and check Add Group Header, then
click OK
The report table looks like this
 Step 4: From Row
groups > select Product group details (group Details and not group header)
> go to Group Properties > select Visibility tab > select Hide >
click on Display can be toggled by this group item and select the name of the
group then click on OK
Step 4: From Row
groups > select Product group details (group Details and not group header)
> go to Group Properties > select Visibility tab > select Hide >
click on Display can be toggled by this group item and select the name of the
group then click on OK
 Then the
preview the report
Then the
preview the report
 Step 5:We can
also change the drill down and make it reverse by setting ‘InitialToggleState’
to True and by selecting the group properties (header), visibility tab and click
Show
Step 5:We can
also change the drill down and make it reverse by setting ‘InitialToggleState’
to True and by selecting the group properties (header), visibility tab and click
Show
Step1: Create New Report Project with one Shared DataSource with data query for generating report.
Step1: Create report by taking Table type report as shown bellow



The report table looks like this



Subscribe to:
Comments (Atom)